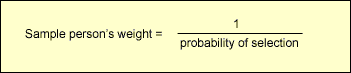
Weights are created in NHANES I to account for the complex survey design (including oversampling), survey non-response, and post-stratification. When a sample is weighted in NHANES I it is representative of the civilian non-institutionalized Census population in the coterminous United States, excluding persons living on American Indian reservations.
Each Sample person in the NHANES I dataset is assigned a sample weight. This sample weight is created in three steps:
In general a sample person is assigned a weight that is equivalent to the reciprocal of his/her probability of selection. In other words:
However, calculating the base weight for a sample person in NHANES I is much more complicated due to the survey's complex, multistage design. In NHANES I, the following equation, which takes into account the survey design, is used to determine the base weight for a sample person:
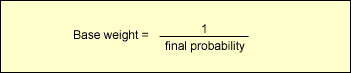

Adjustment to the interview or exams
The base weights were adjusted for non-response to the MEC exam. The reciprocal of the probability of selection of the sample persons is multiplied by a factor that brings the estimates based on examined persons up to a level that would have been attained if all sample persons had been examined. This non-response adjustment factor was computed separately within relatively homogeneous classes defined by five income groups (under $3,000; $3,000-$6,999; $7,000-$9,999; $10,000-$14,999; $15,000 or more) within each stand. The factor is the ratio of the sum of the sample weights for all sample persons to the sum of sampling weights for all responding sample persons within the same homogeneous class.
In NHANES I, the response rates for the in-home interview were over 98%. Thus, an individual was classified as a non-respondent only to the exam portion of the survey if they agreed to complete the interview but did not agree to, or come in for, the MEC portion of the survey. Adjustments made for survey non-response account only for exam non-response, but not for component/item non-response (i.e., a sample person declined to have their blood pressure measured in the examination component but completed all other examination components). Under certain conditions, missing data were imputed. There are variables in the data files which indicate whether the data were imputed. Please see the specific file description for the criteria used to create the imputations.
Finally, some variables appear to have a great deal of missing data, but that is only because the NHANES design dictated that the item was to be obtained only for a particular subsample. One asterisk means the data were obtained only on examinees at stands 1-65. Two asterisks denote that the data were obtained from examinees in stands 66-100. Three asterisks denote that the data were obtained only for examinees receiving the detailed examination. Four asterisks denoted items obtained only for detailed examinees from stands 1-35, and five asterisks are for items obtained only on respondents aged 1-17 years.
In general for NHANES I, 32,000 persons were selected into the sample, 31,973 completed the interview, and 23,808 were MEC examined. For detailed response rates by age and other selected demographic characteristics, please click the link below to see the Table of Response Rates for NHANES I.
For more information on sample design, weighting, non-response, variance estimation and other important analytical considerations, see
1. A Statistical Methodology for Analyzing Data From a Complex Survey: The First National Health and Nutrition Examination Survey. Landis, J. R., Lepkowski, J. M., Eklund, S. A., Stehouwer, S. A. September 1982. 58 pp. (PHS) 82-1366. PB88-226949. PC A04 MF A01.
Or http://www.cdc.gov/nchs/data/series/sr_02/sr02_092.pdf
For more information on component/item non-response adjustment and re-weighting the data for analyses, see
1. Lohr, Sharon L. Sampling: Design and Analysis, pp.265-272. Duxbury Press, 1999.
NHANES I was conducted in several stages. The initial design from April 1971 through June 1974 provided for the selection of a representative sample of the target population 1-74 years of age, in 65 survey locations (or stands). All 20,749 examined persons received a specifically designed nutrition-related examination. In addition, approximately 20% of those ages 25-74 years (3,854 persons) received a more detailed examination and questionnaire. Furthermore, an additional 3,059 persons ages 25-74 were examined in the subsequent 35 locations in an Augmentation Survey which was conducted from July 1974 to September 1975. Finally, the first 35 stands of the initial 65 location survey became an independent, representative sample in order to provide for early estimates of a number of nutrition-related factors, and because some components of the initial examination could no longer be continued.
In summary, there are 6 different survey samples which can be analyzed:
For response rates by total survey and subsample components, see the tables below.
| Sample | Sample Size | Number Interviewed |
Percent Interviewed |
Number Examined |
Percent Examined |
|---|---|---|---|---|---|
| Original Sample (Stands 1-65) | 28,043 | 27,753 | 99.0 | 20,749 | 74.0 |
| Augmentation Survey (Stands 66-100) | 4,288 | 4,220 | 98.4 | 3,059 | 71.3 |
| Total Participants | 32,331 | 31,973 | 98.9 | 23.808 | 73.6 |
| Sample | Sample Size | Number Interviewed |
Percent Interviewed |
Number Examined |
Percent Examined |
|---|---|---|---|---|---|
| Detailed Subsample (Stands1-65) | 5,593 | 5,522 | 98.7 | 3,854 | 68.9 |
| Augmentation Survey (Stands 66-100) | 4,288 | 4,220 | 98.4 | 3,059 | 71.3 |
| Total Detailed Subsample (Stands 1-100) | 9,881 | 9,742 | 99.0 | 6,913 | 70.0 |
| Sample | Sample Size | Number Interviewed |
Percent Interviewed |
Number Examined |
Percent Examined |
|---|---|---|---|---|---|
| Initial (35 Stands) | 14,147 | 13,969 | 98.7 | 10,127 | 71.6 |
| Detailed Subsample (Stands 1-35) | 2,798 | 2,753 | 98.4 | 1,892 | 67.6 |
Each of these samples has its own designated weight, which accounts for the specific probability of selection into that sample, as well as the appropriate non-response.
These sample weights are not designed to be combined. In fact, they are mutually exclusive. If it is necessary to combine two or more samples for your analyses, then appropriate weights would need to be recalculated. However, details on how to recalculate weights when combining samples go well beyond the scope of this tutorial. Therefore, it is strongly advised that you do not attempt to combine samples in any analysis of NHANES I data.
In addition to accounting for sample person non-response, weights are also post-stratified to match the population control totals for each sampling subdomain. This additional adjustment makes the weighted counts the same as independent controls prepared by the U.S. Bureau of the Census for the non-institutionalized population of the United States as of November 1, 1972 (the approximate mid-point of the survey).
In summary, it is important to utilize the weights in analyses to account for the complex survey design (including oversampling), survey non-response, and post-stratification in order to ensure that calculated estimates are truly representative of the U.S. civilian non-institutionalized population.