There are several steps to loading the text data files and saving them as permanent Stata datasets:
To decide which variables you need (or just to see what is available) go to the NHANES documentation. In your Stata example, you will use the documentation downloaded in Task 2, the Adult documentation file, to learn about the adult data. The documentation tells you how to decipher the data file.
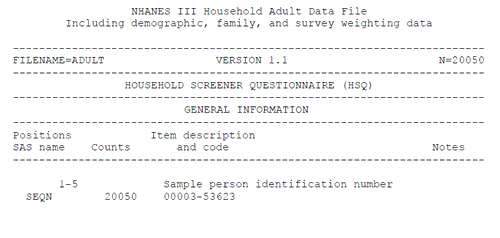
In the Adult documentation file, search for "item description". The second instance should be the beginning of the Data File index. This list describes each item. There are four columns: "Positions/SAS name", "Counts", "Item description and code", and "Notes". The Positions column indicates where the variable is located in the raw data file and the SAS name for the item. The "Counts" column tells you how many observations are available. The "Item description and code" column gives the English text and codes used for that item. The Notes column provides additional notes for that item following the data file index.
Figure: Screenshot of NHANES III Adult Data File
Documentation Data File Index
Like the name sounds, the dictionary defines the data. It tells the computer where to look in those blocks of numbers to find the variables you want in the dataset and how to name the variables. It even lets you give the variables more descriptive labels. You will create the data dictionary in Stata's do-file editor.
The dictionary gives STATA instructions on reading the raw data file. A simple data dictionary looks like this:
dictionary{
_column(1) seqn
%5.0f "id number"
_column(15) hssex
%1.0f "sex"
_column(18) hsageir
%2.0f "age in years"
}
There are two types of variables in Stata — numbers and strings. Because NHANES codes data using only numbers, this example will only show you how to read in number variables. Now, let's look at each part of the dictionary in more detail:
The dictionary{} command notifies Stata that the following code is a dictionary file. The _column() command tells Stata where to look for the variable in the raw data file by indicating the beginning location in the parenthesis. The beginning location of the variable within each record can be found in the data file index of the documentation under the "Position" heading (Note: What the data file index refers to as a "position" is referred to as "column" in Stata.)
Then, you provide a name for the variable. In Stata 9 and 10, variable names can be up to 32 characters long. NHANES assigns names to all variables and to maintain continuity with the documentation, you may choose to name your variables the same way. However, you may also create your own names following the naming rules outlined in the Stata manual. NHANES variable names can be found under the "SAS name" heading of the data file index.
Stata is case-sensitive. For example, as far as STATA is concerned, feh ≠Feh. If you use capital letters in the dictionary, you will always have to type capital letters to refer to that variable.
Next, you will need to tell Stata how wide the variable is using the %X.Yf format. X indicates how many digits are in the variable. Y indicates the minimum number of digits to the right of the decimal point. Enter 0 here, as this will only affect how the output looks and does not change the actual values. To calculate the width of the variable, use this:
variable width = (end position - beginning position) + 1
For example, the data file index says that the variable SEQN (the person's identification number) is in position 1-5. That means the variable starts at position 1 and goes to position 5 and is five columns wide.
Finally, save the data dictionary in your C:\NHANES III\Data folder. Use the dictionary option in the Save As menu to automatically add the .dct extension.
Once you have a dictionary you can use it to load the data into STATA. The general syntax is:
infile using <path to dictionary>, using(<path to data file>)
Using the dictionary file you created in the previous step and the data file you downloaded in the previous module, your example should look like this:
infile using "c:\nhanes iii\data\adult.dct", using ("c:\nhanes iii\data\adult.dat")