Task 4: Key Concepts about Using Balanced Repeated Replication (BRR)
NHANES survey design affects variance estimates
As stated in the module on sampling in NHANES (Continuous Tutorial, Module 10), the NHANES has a complex, multistage, probability cluster design. Typically, individuals within a cluster (e.g., county, school, city, census block) are more similar to one another than to those in other clusters and this homogeneity of individuals within a given cluster is measured by the intra-cluster correlation. When working with a complex sample, it is preferable to decrease the amount of correlation between sample persons within clusters. To achieve this, we recommend sampling fewer people within each cluster but sampling more clusters. However, because of operational limitations (e.g., cost of moving the survey mobile examination centers [MECs], and geographic distances between primary sampling units [PSUs]), NHANES can sample only 30 PSUs within a 2-year survey cycle. The sample size in each PSU is roughly equal and it is intended to yield about 5,000 examined persons per year.
In a complex sample survey setting such as NHANES, variance estimates computed using standard statistical software packages that assume simple random sampling are generally too low (i.e., significance levels are overstated) and biased because they do not account for the differential weighting and the correlation among sample persons within a cluster. Some statistical software packages can incorporate differential weighting, but only a few account for both differential weighting and the correlation among sample persons.
Standard statistical software packages that assume simple random sampling calculate variance estimates that are generally too low and biased because they do not account for differential weighting and the correlation among sample persons within a cluster.
Balanced repeated replication (BRR) is a statistical method for estimating sampling variability of a statistic, taking into account NHANES’ complex sample design. This method is described in the following section.
Overview of Balanced Repeated Replication
In BRR, half of the sample is used at a time, including one of two PSUs from each stratum. The variance of the parameter of interest, 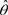 , is estimated by calculating the parameter for a half sample, h , repeating this process for many half samples, and then computing the variances of the different parameter estimates. When the parameter is computed for the half sample, the sample weights of the observations in the PSUs are doubled. For H half samples, the variance is given by:
, is estimated by calculating the parameter for a half sample, h , repeating this process for many half samples, and then computing the variances of the different parameter estimates. When the parameter is computed for the half sample, the sample weights of the observations in the PSUs are doubled. For H half samples, the variance is given by:
Equation 1.
With S strata, 2S replicates can be formed. However, it is possible to pick the half samples according to a particular pattern so that just some of the possible replicates are chosen; this is what is done in BRR. The pattern is from a Hadamard matrix. The Hadamard matrix is used to select the H “balanced” replicates. The number of replicates that are needed for BRR is the smallest integer that is divisible by 4 and is greater than or equal to S. For 2 years of NHANES data, this number is 16.
The method described in equation (1) above is standard BRR. In some situations, a modification of BRR, called Fay’s method is needed to compute standard errors. In this method, the sample weights from BRR are not zero weighted in one half of the sample, and double-weighted in the other half. Instead, they are weighted by a factor F (F is a proportion that ranges between 0 and 1). This factor weights down one half of the sample by F, and the other half is weighted up by 2-F. For example, when F=0.3, the weights are decreased by 30% in one half sample and increased by 70% in the other half sample. The weights given in the dataset demoadv for the advanced dietary tutorial use F=0.3. When Fay’s method is used, the estimated variance is computed as:
Equation 2.
Modeling the complex survey structure of NHANES requires procedures that account for both differential weighting of individuals and the correlation among sample persons within a cluster. The NCI method calls the SAS procedure NLMIXED, which can account for differential weighting by using the replicate statement. The use of BRR to calculate standard errors accounts for the correlation among sample persons in a cluster. Therefore, NLMIXED (or any SAS procedure that incorporates differential weighting) may be used with BRR to produce standard errors that are suitable for NHANES data without using specialized survey procedures.
Note: The SAS procedure NLMIXED requires the use of integer weights.
Reference:
Korn EL, Graubard BI. Analysis of Health Surveys. Wiley, New York, 1999.